
A Primer on Mutations, Variants and Sequencing.
-Anu Acharya , Mapmygenome
20 years ago, when I took a sudden dive into the world of genomics, its terminology was restricted to the tiny genomic universe where I found myself thriving. The outside world knew it as an interesting thing that one never has to know much about. Over the years, awareness in the public regarding DNA testing and sequencing increased as tests became accessible to patients, doctors and consumers. However, never before has the world seen such an explosion in terms of awareness of sequencing terminology, genome sequencing, RT-PCR, and so much more. Speaking to some friends and reading some comments online, I thought it may be good to simplify the lingo used so that it may be better understood.
Last year in April, I wrote a blog on Sequencing (Sequence!, Sequence!, Sequence!), urging India to sequence more to understand if mutations were occurring in the virus as it impacts several things including testing, vaccines and drugs and thereby affecting public health policy as well.
The Department of Biotechnology this year created INSACOG to help sequence more of the samples in India. That target is 5% of the positive samples India gets. That is a fabulous target as the world’s most sequenced nation (UK) sequences about 10% of the cases. The USA sequences around 2%. To put things in perspective, we have only sequenced around 20,000 viral samples in people who tested positive. The plan is to expand this tremendously. This can truly help us understand if we can expect more variants and if they will impact any of the vaccines, infection rate, drugs, RT PCR tests, etc. Understanding sequences of genomes globally gives us a better perspective on the origin, transmission, genetic diversity and outbreak dynamics as well.
This is an evolutionary game between the virus and the host( human in this case). From the virus’s perspective, its survival is dependent on infecting more people and evading the drugs and the immune memory developed through vaccines that humans create. The longer it stays in a host and the more hosts it infects, the higher the chances of replication and errors in that process resulting in mutations. Several mutations lead to a variant when it has a change in its ability to infect, transmit or cause severe disease. The mutations that render the virus ineffective do not get studied as we typically look for the virus in the host it infects.
As new drugs and vaccines try to stop the replication, the virus needs to find ways to continue its growth trajectory and thus mutated versions are the ones that come up. In the battle between the virus and the human, prevention is the cure. The sooner we vaccinate large populations in a short period, the faster we can win. During this process, we need to ensure that other preventive measures are being taken by the global human community including masking and other hygiene measures.
So, why is there a hullabaloo about genomic sequencing and what are these variants that get people emotionally charged as countries get associated with them?
Most people are now familiar with the ball-like structure shown on TV, in newspapers etc. If we had to break it down to its bases, it would be around 29,000 base pairs. In comparison, we humans have around 3.2 billion base pairs. A viral sequencing would show changes to the original sequencing sample that was submitted in December of 2019 by scientists from China. That sequence is considered to be the base sequence. Any change in that would be considered a mutation. Now there will be thousands of mutations found in different parts of the genome but many of them may not make any difference in terms of how the virus enters our body and causes disease. If we could roll out the virus-like a roll of paper, it would look something like this.
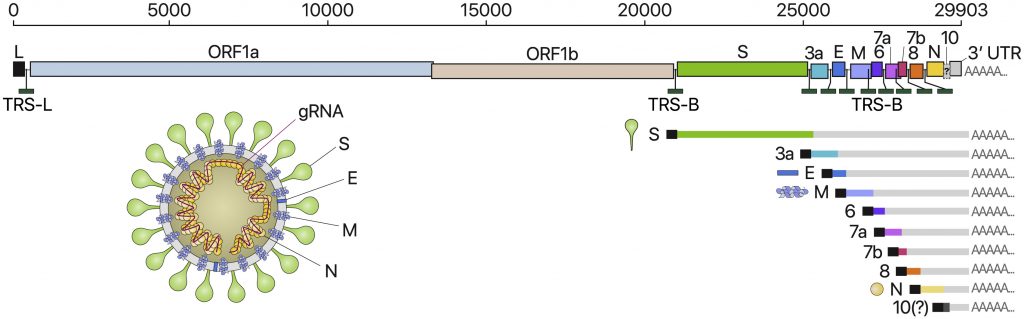
Source: Cell Article: https://www.sciencedirect.com/science/article/pii/S0092867420304062
The area of interest is found in the spike protein(green coloured S region), especially the RBD region or the receptor-binding domain. Basically, this is the region that attaches to the ACE2 receptors found in the human cells. When we sequence the virus, we get data in the form of A, C, T, G. For those who are wondering about the RNA vs DNA. We would do a reverse transcription and make a cDNA library to create the actual DNA sequences.
You may wonder how a small change makes a difference then? Well, from high school biology you may remember amino acids. Three bases code for an amino acid.
When we first started Ocimum Biosolutions, I wanted to name our servers as amino acids. The idea was shot down but helps me remember some of the names even now. These are important to understand as these are the letters that you will see in various mutations. There are 20 essential amino acids and a couple more adding to 22 amino acids. Some that you may have heard in the COVID context would be N (Asparagine), K (Lysine), D (Aspartic Acid), G (Glycine), and P( Proline).
Any change from the original sequence as published by Chinese scientists in December 2019 that is known as the wild type is known as a mutation. They can be of various types. In English let’s assume that we had a sentence that went like “Please reserve a birth in advance” when it was meant to say “Please reserve a berth in advance”. As you can see it changes the meaning of the sentence. Similarly when a letter is replaced it changes the protein and its structure entirely.
In the same way, when a virus makes copies of itself, it can make copying errors of various kinds.
Commonly found Missense mutations: Here a single letter is copied wrong resulting in what we call a point mutation. But as explained above, it can change the amino acid.
- E484K nicknamed Eek by some scientists is a change in the amino acid at position 484 from E to K in the spike protein that is coloured green. For example E ( glutamic acid stands for either GAA or GAG. K which is Lysine codes for AAA or AAG. So if the first letter changes from G to A, it would change it from glutamic acid to Lysine. This is hypothesized to evade antibodies.
- Similarly, we have other mutations like N440K, N501Y (Nelly), A222V, K417N, L452R, D614G( Doug) that makes it more transmissible.
Famous Deletions
- 69-70del also known as HV 69/70 is caused by a deletion of 6 bases in the RNA causing 2 amino acids to be deleted. In case you have forgotten, one amino acid is made up of 2 base pairs coding for an amino acid.
And there are insertions where extra bases are added etc.
Naming Variants
A collection of mutations with a significant change in function is called a variant. The (in)famous ones that got attached to a country where it was first discovered.
There are many naming conventions that are likely to confuse you. The ones that you see with A and B prefix come from a system known as Pangolin. The other systems include Nextstrain. The WHO recently came up with a new system. ( Updating this part since this came out after I published this)
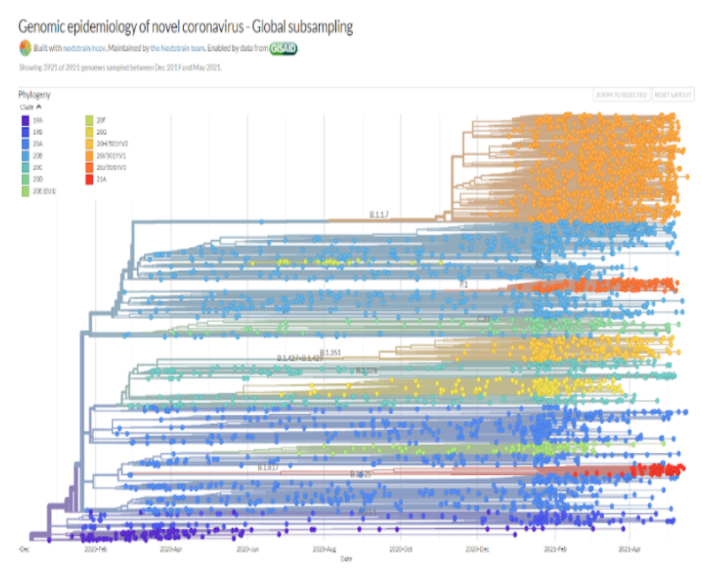
While I prefer to keep countries out of naming variants, some became too popular by the country names, unfortunately. The Pangolin names start with A or B. As we see in major software updates the names are often with decimals signifying the updates to the original version. When a tree is drawn of all sequences, we can start to see how beautifully it branches out. I have a screenshot of the latest variants from the Nextstrain website.
As you can see one variant comes from another and the world is a melting pot of mutations and vicious cycles are formed between mutations and infections. The more the infections, the more the mutations and vice versa.
The Variants of concern that the WHO has named are
B.1.117 or Alpha variant that was first sequenced in the UK has 17 acquired mutations including N501Y( Nelly) and D618G(Doug).
B.1.351 or Beta was first sequenced in South Africa. It has some common mutations like N501Y( Nelly) but also has a new mutation E484K(Eek) that potentially evades antibodies.
The B.1.1.28 or Gamma first sequenced in Brazil also known as P1 or P2 also has the dreaded E484K( Eek) that allows it to evade antibodies to some extent.
B.1.617.2 or Delta that was first sequenced in Maharashtra, India in October 2020 has 15-17 mutations including E484K(Eek), L452R, E484Q, P681R . The recent B.1.617.2 is an extension of B.1.617 and has key mutations namely L452R, T478K and P681R.
The WHO has also named some Variants of interest with Greek letters.
B.1.617.2 or Delta also sequenced first in India.
B.1.427/B.1.429 first sequenced in the USA as Epsilon
P.2 or Zeta first sequenced in Brazil
P.3 or Theta first sequenced in the Phillippines
B.1.525 or Eta found simultaneously in many countries
| B.1.526 or Iota first sequenced in the USA |
There are many ways to sequence any organism. The three main methods for doing a Whole-genome sequencing for covid include
- Metagenomic sequencing: Here we sequence all possible organisms including human, bacteria, virus and fungi in a sample. Probably the cheapest of the methods but may not be very useful for low viral loads.
- Target enrichment sequencing: In this case, regions of interest are captured by hybridization of Oligos to target-specific probes.
- Amplicon sequencing: Here we take small segments of the virus, amplify them using PCR and do a deep sequencing of those regions.
- Multiplex PCR is a newer method and can help in getting a consensus sequence rather quickly and has found a lot of use in the outbreak.
Some of the well-known companies that have instruments for sequencing include Illumina, Oxford Nanopore, BGI etc. There are also many newer instruments and technologies that are coming up.
By Sequencing variants globally, we can understand the origin and spread of the virus and understand its disease dynamics. Sequencing will also help us create more sensitive tests for better detection through RTPCR, tailored treatment and effective vaccines made for different strains.
More importantly with enough data, we can predict its behaviour and design mitigation strategies. In this game between the virus and the human, we need a few tricks to stay ahead of the game.
“We are survival machines – robot vehicles blindly programmed to preserve the selfish molecules known as genes. This is a truth which still fills me with astonishment.”
– Richard Dawkins, The Selfish Gene